Features
- Side-by-Side Comparison: Simultaneously evaluate multiple LLMs to understand how they perform in real-time across various scenarios.
- Performance Metrics: Examine essential performance indicators like response time and token usage to gain deeper insights into each LLM’s capabilities.
- Response Comparison: Compare the responses generated by different LLMs, assessing the quality, relevance, and appropriateness for specific tasks.
- Cost Analysis: Evaluate the cost implications of using different LLMs, helping you balance budget constraints with performance needs.
- Intuitive Interface: Use a user-friendly interface that simplifies the process of setting up tests, visualizing results, and making comparisons.
- Comprehensive Reporting: Generate detailed reports that compile and visualize comparison data, supporting informed decision-making.
Get started
List existing experiments
Get a quick overview of all experiments created.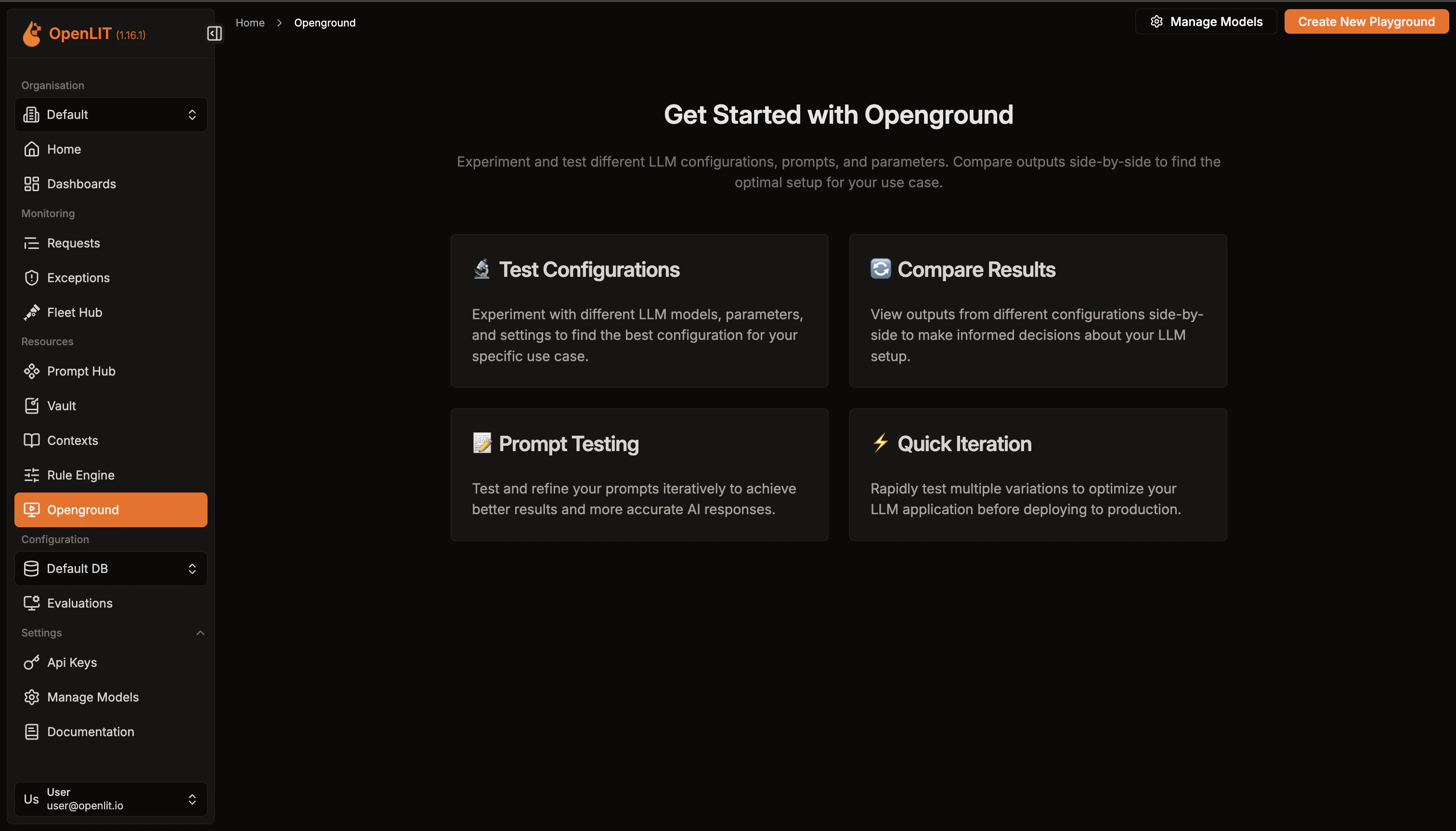
- Navigate to the OpenGround in OpenLIT.
- Explore the previosly created experiments.
Create a new experiment
Set up new experiments to compare different LLMs side-by-side.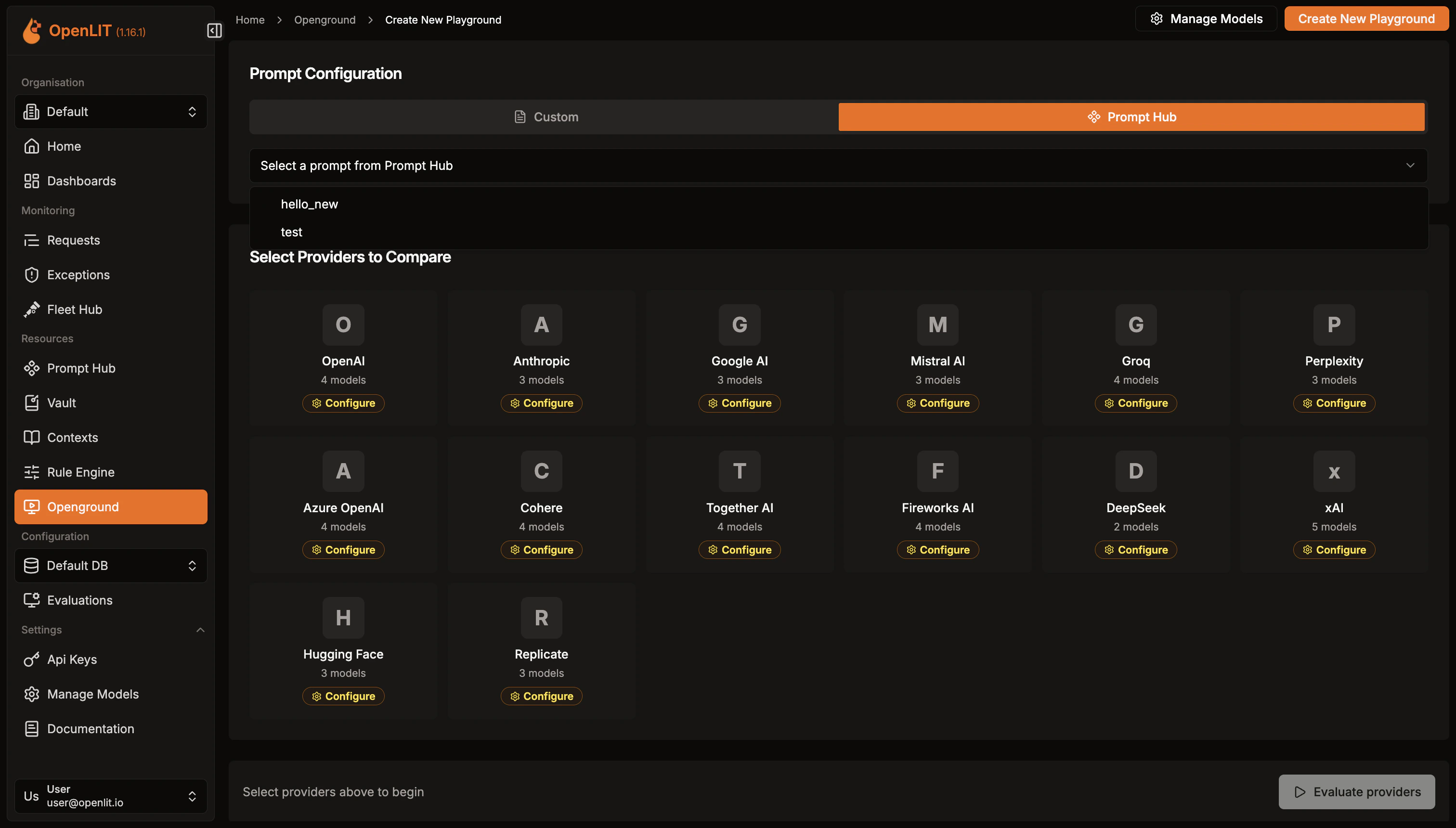
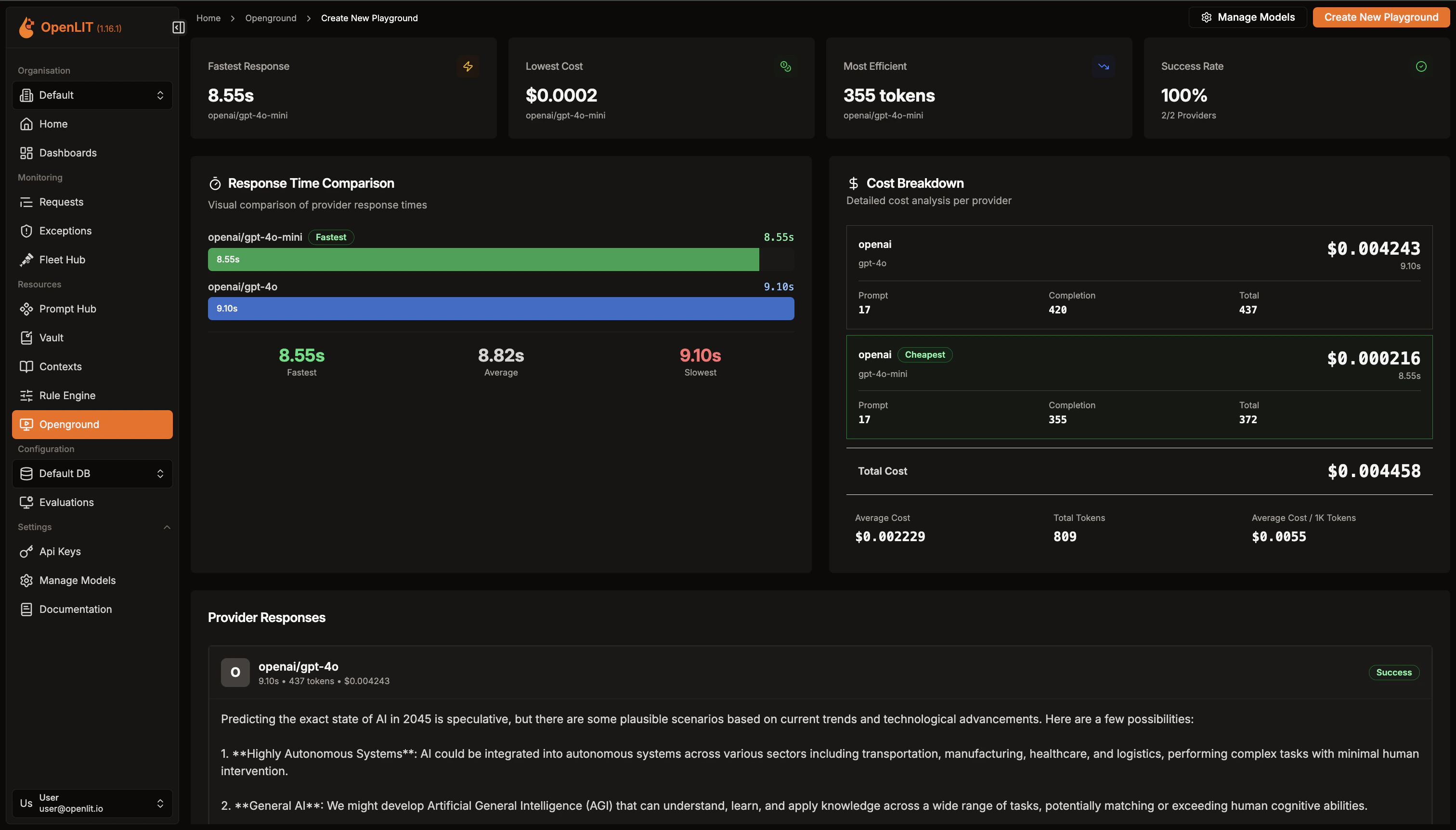
- Click on Create new button to start a new experiment.
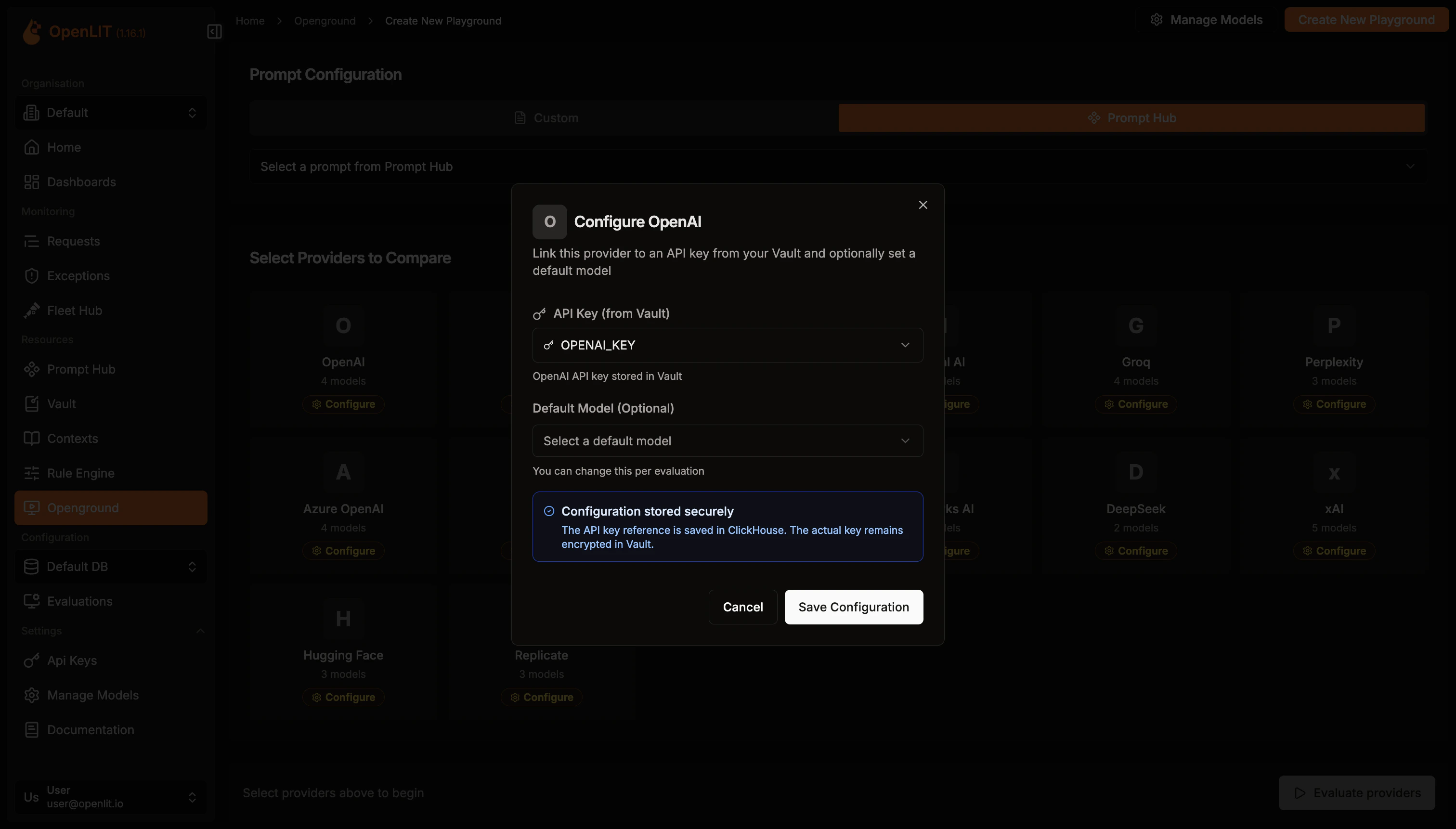
- In the editor, choose your first LLM provider. Configure the LLM by setting its parameters and enter your API key to enable requests.
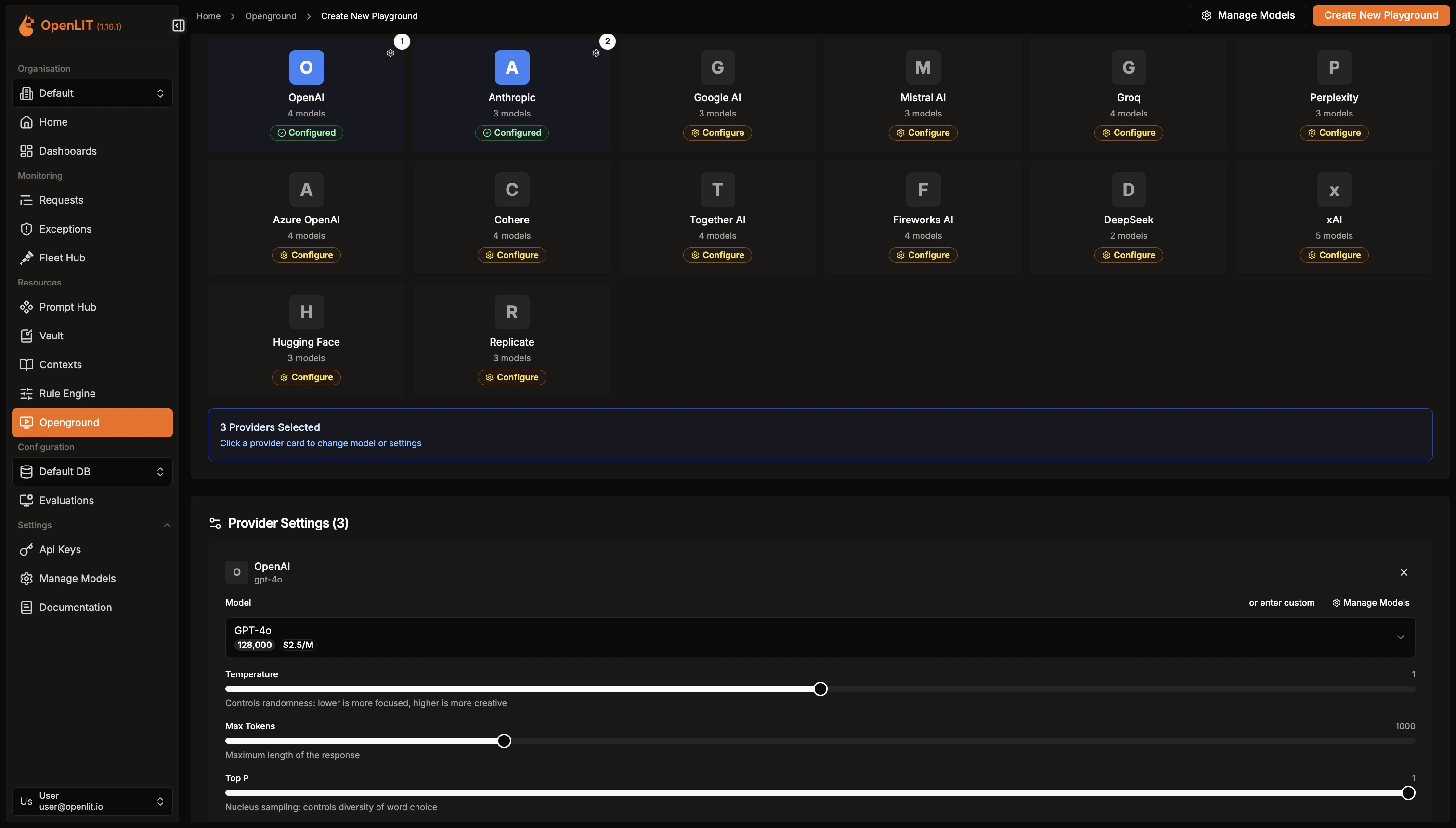
- Repeat the process for your second LLM provider. Choose the provider and configure its LLM parameters.
- Once both LLMs are set up, enter your prompt and click Compare Response.
- Review and analyze the responses from both LLMs to see how they compare.
Manage LLM secrets
Centrally store LLM API keys that applications can retrieve remotely without restarts
Create a dashboard
Create custom visualizations with flexible widgets, queries, and real-time AI monitoring
Manage prompts
Version, deploy, and collaborate on prompts with centralized management and tracking
Zero-code observability with the OpenLIT Controller
Discover and instrument LLM traffic across Kubernetes, Docker, and Linux using eBPF — no code changes required.